22. Simple Neural Network Regression with Keras and JAX#
GPU
This lecture was built using a machine with access to a GPU — although it will also run without one.
Google Colab has a free tier with GPUs that you can access as follows:
Click on the “play” icon top right
Select Colab
Set the runtime environment to include a GPU
In this lecture we show how to implement one-dimensional nonlinear regression using a neural network.
We will use Keras, a popular and relatively simple library for deep learning.
The emphasis in Keras is on providing an intuitive API, while the heavy lifting is done by one of several possible backends.
Currently the backend library options are TensorFlow, PyTorch, and JAX.
In this lecture we will use JAX.
Our main task is to provide an elementary introduction to deep learning in a regression setting.
Later, in a separate lecture, we will investigate how to do the same learning task using JAX directly, rather than relying on Keras.
We begin this lecture with some standard imports.
import numpy as np
import matplotlib.pyplot as plt
Let’s install Keras.
!pip install keras
Now we specify that the desired backend is JAX.
import os
os.environ['KERAS_BACKEND'] = 'jax'
Now we should be able to import some tools from Keras.
Note
Without setting the backend to JAX, the imports below might fail (unless you have PyTorch or TensorFlow set up).
If you have problems running the next cell in Jupyter, try
quitting
running
export KERAS_BACKEND="jax"starting Jupyter on the command line from the same terminal.
import keras
from keras import Sequential
from keras.layers import Dense
22.1. Data#
First let’s write a function to generate some data.
The data has the form
where
the input sequence \((x_i)\) is an evenly-spaced grid,
\(f\) is a nonlinear transformation, and
each \(\epsilon_i\) is independent white noise.
Here’s the function that creates vectors x and y according to the rule
above.
def generate_data(x_min=0, # Minimum x value
x_max=5, # Max x value
data_size=400, # Default size for dataset
seed=1234):
rng = np.random.default_rng(seed)
x = np.linspace(x_min, x_max, num=data_size)
ϵ = 0.2 * rng.standard_normal(data_size)
y = x**0.5 + np.sin(x) + ϵ
# Keras expects two dimensions, not flat arrays
x, y = [np.reshape(z, (data_size, 1)) for z in (x, y)]
return x, y
Now we generate some data to train the model.
x, y = generate_data()
Here’s a plot of the training data.
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
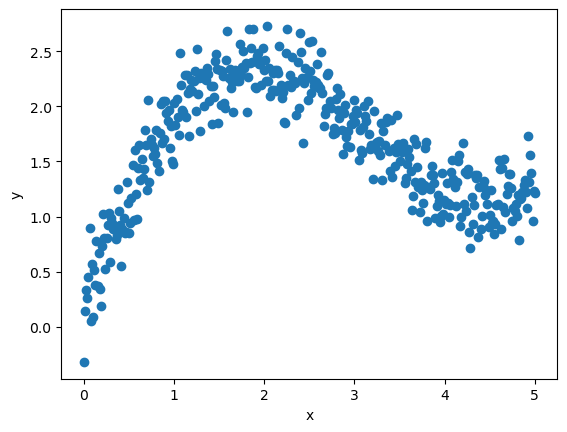
We’ll also use data from the same process for validation.
x_validate, y_validate = generate_data(seed=5678)
22.2. Models#
We supply functions to build two types of models.
22.2.1. Regression model#
The first implements linear regression.
This is achieved by constructing a neural network with just one layer, that maps to a single dimension (since the prediction is real-valued).
The object model will be an instance of keras.Sequential, which is used to
stack layers into a single prediction model.
def build_regression_model():
# Generate an instance of Sequential, to store layers and training attributes
model = Sequential()
# Add a single layer with scalar output
model.add(Dense(units=1))
# Configure the model for training
model.compile(optimizer=keras.optimizers.SGD(),
loss='mean_squared_error')
return model
In the function above you can see that
we use stochastic gradient descent to train the model, and
the loss is mean squared error (MSE).
The call model.add adds a single layer with the activation function equal to the identity map.
MSE is the standard loss function for ordinary least squares regression.
22.2.2. Deep Network#
The second function creates a dense (i.e., fully connected) neural network with 3 hidden layers, where each hidden layer maps to a 10-dimensional output space.
def build_nn_model(output_dim=10, num_layers=3, activation_function='tanh'):
model = Sequential()
# Add layers to the network sequentially, from inputs towards outputs
for i in range(num_layers):
model.add(Dense(units=output_dim, activation=activation_function))
# Add a final layer that maps to a scalar value, the prediction.
model.add(Dense(units=1))
# Embed training configurations
model.compile(optimizer=keras.optimizers.SGD(),
loss='mean_squared_error')
return model
22.2.3. Tracking errors#
The following function will be used to plot the MSE of the model during the training process.
The MSE should fall as the parameters are adjusted to better fit the data.
def plot_loss_history(training_history, ax):
# Plot MSE of training data against epoch
epochs = training_history.epoch
ax.plot(epochs,
np.array(training_history.history['loss']),
label='training loss')
# Plot MSE of validation data against epoch
ax.plot(epochs,
np.array(training_history.history['val_loss']),
label='validation loss')
# Add labels
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss (Mean squared error)')
ax.legend()
22.3. Training#
Now let’s go ahead and train our models.
22.3.1. Linear regression#
We’ll start with linear regression.
regression_model = build_regression_model()
Now we train the model using the training data.
training_history = regression_model.fit(
x, y, batch_size=x.shape[0], verbose=0,
epochs=2000, validation_data=(x_validate, y_validate))
Let’s have a look at the evolution of MSE as the model is trained.
fig, ax = plt.subplots()
plot_loss_history(training_history, ax)
plt.show()
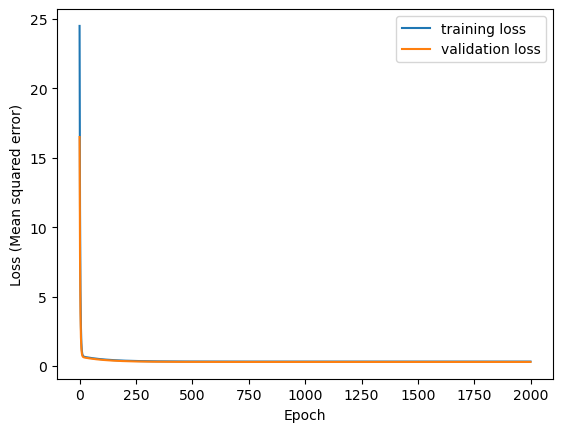
Let’s print the final MSE on the validation data.
print("Testing loss on the validation set.")
regression_model.evaluate(x_validate, y_validate, verbose=2)
Testing loss on the validation set.
13/13 - 0s - 15ms/step - loss: 0.2954
0.2953762412071228
Here’s our output predictions on the validation data.
y_predict = regression_model.predict(x_validate, verbose=2)
13/13 - 0s - 7ms/step
We use the following function to plot our predictions along with the data.
def plot_results(x, y, y_predict, ax):
ax.scatter(x, y)
ax.plot(x, y_predict, label="fitted model", color='black')
ax.set_xlabel('x')
ax.set_ylabel('y')
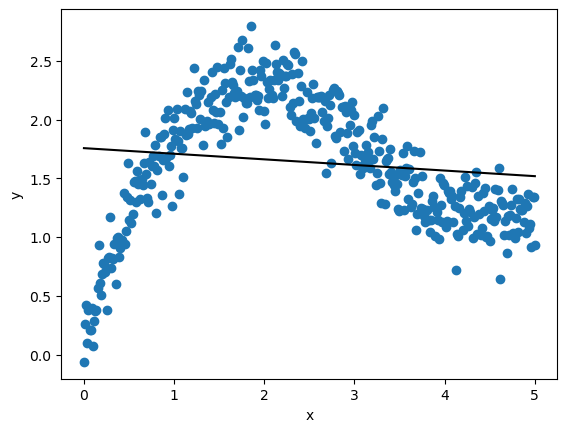
Let’s now call the function on the validation data.
fig, ax = plt.subplots()
plot_results(x_validate, y_validate, y_predict, ax)
plt.show()
22.3.2. Deep learning#
Now let’s switch to a neural network with multiple layers.
We implement the same steps as before.
nn_model = build_nn_model()
training_history = nn_model.fit(
x, y, batch_size=x.shape[0], verbose=0,
epochs=2000, validation_data=(x_validate, y_validate))
fig, ax = plt.subplots()
plot_loss_history(training_history, ax)
plt.show()
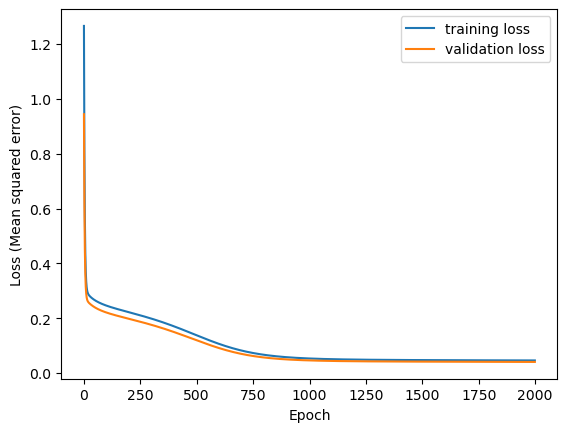
Here’s the final MSE for the deep learning model.
print("Testing loss on the validation set.")
nn_model.evaluate(x_validate, y_validate, verbose=2)
Testing loss on the validation set.
13/13 - 0s - 26ms/step - loss: 0.0408
0.04083334282040596
You will notice that this loss is much lower than the one we achieved with linear regression, suggesting a better fit.
To confirm this, let’s look at the fitted function.
y_predict = nn_model.predict(x_validate, verbose=2)
13/13 - 0s - 20ms/step
fig, ax = plt.subplots()
plot_results(x_validate, y_validate, y_predict, ax)
plt.show()
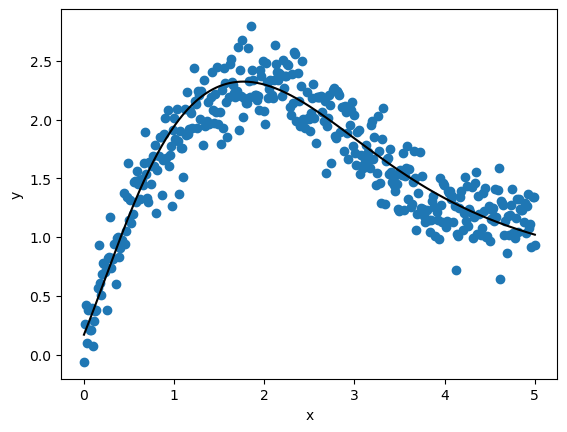
Not surprisingly, the multilayer neural network does a much better job of fitting the data.
In a follow-up lecture, we will try to achieve the same fit using pure JAX, rather than relying on the Keras front-end.