9. An Asset Pricing Problem#
GPU
This lecture was built using a machine with access to a GPU — although it will also run without one.
Google Colab has a free tier with GPUs that you can access as follows:
Click on the “play” icon top right
Select Colab
Set the runtime environment to include a GPU
9.1. Overview#
In this lecture we consider some asset pricing problems and use them to illustrate some foundations of JAX programming.
The main difference from the lecture Asset Pricing: The Lucas Asset Pricing Model, which also considers asset prices, is that the the state spaces will be discrete and multi-dimensional.
Most of the heavy lifting is done through routines from linear algebra.
Along the way, we will show how to solve some memory-intensive problems with large state spaces.
We do this using elegant techniques made available by JAX, involving the use of linear operators to avoid instantiating large matrices.
If you wish to skip all motivation and move straight to the first equation we plan to solve, you can jump to (9.13).
The code outputs below are generated by machine connected to the following GPU
!nvidia-smi
Thu Jul 9 05:42:12 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.105.08 Driver Version: 580.105.08 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 38C P0 33W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
In addition to JAX and Anaconda, this lecture will need the following libraries:
!pip install quantecon
Below we use the following imports
import scipy
import quantecon as qe
import matplotlib.pyplot as plt
import numpy as np
import jax
import jax.numpy as jnp
from collections import namedtuple
from time import time
We will use 64 bit floats with JAX in order to increase precision.
jax.config.update("jax_enable_x64", True)
9.2. Pricing a single payoff#
Suppose, at time \(t\), we have an asset that pays a random amount \(D_{t+1}\) at time \(t+1\) and nothing after that.
The simplest way to price this asset is to use “risk-neutral” asset pricing, which asserts that the price of the asset at time \(t\) should be
Here \(\beta\) is a constant discount factor and \(\mathbb E_t D_{t+1}\) is the expectation of \(D_{t+1}\) at time \(t\).
Roughly speaking, (9.1) says that the cost (i.e., price) equals expected benefit.
The discount factor is introduced because most people prefer payments now to payments in the future.
One problem with this very simple model is that it does not take into account attitudes to risk.
For example, investors often demand higher rates of return for holding risky assets.
This feature of asset prices cannot be captured by risk neutral pricing.
Hence we modify (9.1) to
In this expression, \(M_{t+1}\) replaces \(\beta\) and is called the stochastic discount factor.
In essence, allowing discounting to become a random variable gives us the flexibility to combine temporal discounting and attitudes to risk.
We leave further discussion to other lectures because our aim is to move to the computational problem.
9.3. Pricing a cash flow#
Now let’s try to price an asset like a share, which delivers a cash flow \(D_t, D_{t+1}, \ldots\).
We will call these payoffs “dividends”.
If we buy the share, hold it for one period and sell it again, we receive one dividend and our payoff is \(D_{t+1} + P_{t+1}\).
Therefore, by (9.2), the price should be
Because prices generally grow over time, which complicates analysis, it will be easier for us to solve for the price-dividend ratio \(V_t := P_t / D_t\).
Let’s write down an expression that this ratio should satisfy.
We can divide both sides of (9.3) by \(D_t\) to get
We can also write this as
where
is the growth rate of dividends.
Our aim is to solve (9.5) but before that we need to specify
the stochastic discount factor \(M_{t+1}\) and
the growth rate of dividends \(G^d_{t+1}\)
9.4. Choosing the stochastic discount factor#
We will adopt the stochastic discount factor described in Asset Pricing: The Lucas Asset Pricing Model, which has the form
where \(u\) is a utility function and \(C_t\) is time \(t\) consumption of a representative consumer.
For utility, we’ll assume the constant relative risk aversion (CRRA) specification
Inserting the CRRA specification into (9.6) and letting
the growth rate rate of consumption, we obtain
9.5. Solving for the price-dividend ratio#
Substituting (9.8) into (9.5) gives the price-dividend ratio formula
We assume there is a Markov chain \(\{X_t\}\), which we call the state process, such that
Here \(\{\epsilon_{c, t}\}\) and \(\{\epsilon_{d, t}\}\) are IID and standard normal, and independent of each other.
We can think of \(\{X_t\}\) as an aggregate shock that affects both consumption growth and firm profits (and hence dividends).
We let \(P\) be the stochastic matrix that governs \(\{X_t\}\) and assume \(\{X_t\}\) takes values in some finite set \(S\).
We guess that \(V_t\) is a fixed function of this state process (and this guess turns out to be correct).
This means that \(V_t = v(X_t)\) for some unknown function \(v\).
By (9.9), the unknown function \(v\) satisfies the equation
where \(a := \mu_d - \gamma \mu_c\)
Since the shocks \(\epsilon_{c, t+1}\) and \(\epsilon_{d, t+1}\) are independent of \(\{X_t\}\), we can integrate them out.
We use the following property of lognormal distributions: if \(Y = \exp(c \epsilon)\) for constant \(c\) and \(\epsilon \sim N(0,1)\), then \(\mathbb E Y = \exp(c^2/2)\).
This yields
Conditioning on \(X_t = x\), we can write this as
for all \(x \in S\).
Suppose \(S = \{x_1, \ldots, x_N\}\).
Then we can think of \(v\) as an \(N\)-vector and, using square brackets for indices on arrays, write
for \(i = 1, \ldots, N\).
Equivalently, we can write
where \(K\) is the matrix defined by
Rewriting (9.14) in vector form yields
Notice that (9.16) can be written as \((I - K)v = K \mathbb 1\).
The Neumann series lemma tells us that \(I - K\) is invertible and the solution is
whenever \(r(K)\), the spectral radius of \(K\), is strictly less than one.
Once we specify \(P\) and all the parameters, we can
obtain \(K\)
check the spectral radius condition \(r(K) < 1\) and, assuming it holds,
compute the solution via (9.17).
9.6. Code#
We will use the power iteration algorithm to check the spectral radius condition.
The function below computes the spectral radius of A.
def power_iteration_sr(A, num_iterations=15, seed=1234):
" Estimates the spectral radius of A via power iteration. "
# Initialize
key = jax.random.key(seed)
b_k = jax.random.normal(key, (A.shape[1],))
sr = 0
for _ in range(num_iterations):
# calculate the matrix-by-vector product Ab
b_k1 = jnp.dot(A, b_k)
# calculate the norm
b_k1_norm = jnp.linalg.norm(b_k1)
# Record the current estimate of the spectral radius
sr = jnp.sum(b_k1 * b_k)/jnp.sum(b_k * b_k)
# re-normalize the vector and continue
b_k = b_k1 / b_k1_norm
return sr
power_iteration_sr = jax.jit(power_iteration_sr)
The next function verifies that the spectral radius of a given matrix is \(< 1\).
def test_stability(Q):
"""
Assert that the spectral radius of matrix Q is < 1.
"""
sr = power_iteration_sr(Q)
assert sr < 1, f"Spectral radius condition failed with radius = {sr}"
In what follows we assume that \(\{X_t\}\), the state process, is a discretization of the AR(1) process
where \(\rho, \sigma\) are parameters and \(\{\eta_t\}\) is IID and standard normal.
To discretize this process we use QuantEcon.py’s tauchen function.
Below we write a function called create_model() that returns a namedtuple storing the relevant parameters and arrays.
Model = namedtuple('Model',
('P', 'S', 'β', 'γ', 'μ_c', 'μ_d', 'σ_c', 'σ_d'))
def create_model(N=100, # size of state space for Markov chain
ρ=0.9, # persistence parameter for Markov chain
σ=0.01, # persistence parameter for Markov chain
β=0.98, # discount factor
γ=2.5, # coefficient of risk aversion
μ_c=0.01, # mean growth of consumption
μ_d=0.01, # mean growth of dividends
σ_c=0.02, # consumption volatility
σ_d=0.04): # dividend volatility
# Create the state process
mc = qe.tauchen(N, ρ, σ)
S = mc.state_values
P = mc.P
# Shift arrays to the device
S, P = map(jax.device_put, (S, P))
# Return the namedtuple
return Model(P=P, S=S, β=β, γ=γ, μ_c=μ_c, μ_d=μ_d, σ_c=σ_c, σ_d=σ_d)
Our first step is to construct the matrix \(K\) defined in (9.15).
Here’s a function that does this using loops.
def compute_K_loop(model):
# unpack
P, S, β, γ, μ_c, μ_d, σ_c, σ_d = model
N = len(S)
K = np.empty((N, N))
a = μ_d - γ * μ_c
for i, x in enumerate(S):
for j, y in enumerate(S):
e = np.exp(a + (1 - γ) * x + (σ_d**2 + γ**2 * σ_c**2) / 2)
K[i, j] = β * e * P[i, j]
return K
To exploit the parallelization capabilities of JAX, let’s also write a vectorized (i.e., loop-free) implementation.
def compute_K(model):
# unpack
P, S, β, γ, μ_c, μ_d, σ_c, σ_d = model
N = len(S)
# Reshape and multiply pointwise using broadcasting
x = np.reshape(S, (N, 1))
a = μ_d - γ * μ_c
e = np.exp(a + (1 - γ) * x + (σ_d**2 + γ**2 * σ_c**2) / 2)
K = β * e * P
return K
These two functions produce the same output:
model = create_model(N=10)
K1 = compute_K(model)
K2 = compute_K_loop(model)
np.allclose(K1, K2)
True
Now we can compute the price-dividend ratio:
def price_dividend_ratio(model, test_stable=True):
"""
Computes the price-dividend ratio of the asset.
Parameters
----------
model: an instance of Model
contains primitives
Returns
-------
v : array_like
price-dividend ratio
"""
K = compute_K(model)
N = len(model.S)
if test_stable:
test_stability(K)
# Compute v
I = np.identity(N)
ones_vec = np.ones(N)
v = np.linalg.solve(I - K, K @ ones_vec)
return v
Here’s a plot of \(v\) as a function of the state for several values of \(\gamma\).
model = create_model()
S = model.S
γs = np.linspace(2.0, 3.0, 5)
fig, ax = plt.subplots()
for γ in γs:
model = create_model(γ=γ)
v = price_dividend_ratio(model)
ax.plot(S, v, lw=2, alpha=0.6, label=rf"$\gamma = {γ}$")
ax.set_ylabel("price-dividend ratio")
ax.set_xlabel("state")
ax.legend(loc='upper right')
plt.show()
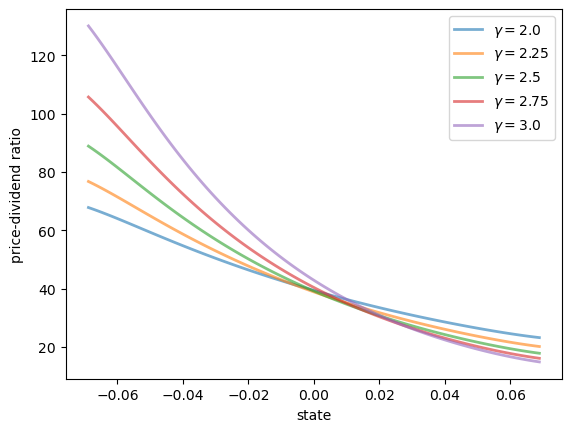
Notice that \(v\) is decreasing in each case.
This is because, with a positively correlated state process, higher states indicate higher future consumption growth.
With the stochastic discount factor (9.8), higher growth decreases the discount factor, lowering the weight placed on future dividends.
9.7. An Extended Example#
One problem with the last set is that volatility is constant through time (i.e., \(\sigma_c\) and \(\sigma_d\) are constants).
In reality, financial markets and growth rates of macroeconomic variables exhibit bursts of volatility.
To accommodate this, we now develop a stochastic volatility model.
To begin, suppose that consumption and dividends grow as follows.
where \(\{Z_t\}\) is a finite Markov chain and \(\{H^c_t\}\) and \(\{H^d_t\}\) are volatility processes.
We assume that \(\{H^c_t\}\) and \(\{H^d_t\}\) are AR(1) processes of the form
Here \(\{\eta^c_t\}\) and \(\{\eta^d_t\}\) are IID and standard normal.
Let \(X_t = (H^c_t, H^d_t, Z_t)\).
We call \(\{X_t\}\) the state process and guess that \(V_t\) is a function of this state process, so that \(V_t = v(X_t)\) for some unknown function \(v\).
Modifying (9.10) to accommodate the new growth specifications, we find that \(v\) satisfies
where, as before, \(a := \mu_d - \gamma \mu_c\)
Conditioning on state \(x = (h_c, h_d, z)\), this becomes
As before, we integrate out the independent shocks and use the rules for expectations of lognormals to obtain
Let
where \(P, Q, R\) are the stochastic matrices for, respectively, discretized \(\{H^c_t\}\), discretized \(\{H^d_t\}\) and \(\{Z_t\}\),
With this notation, we can write (9.20) more explicitly as
Let’s now write the state using indices, with \((i, j, k)\) being the indices for \((h_c, h_d, z)\).
Then (9.21) becomes
One way to understand this is to reshape \(v\) into an \(N\)-vector, where \(N = I \times J \times K\), and \(A\) into an \(N \times N\) matrix.
Then we can write (9.22) as
Provided that the spectral radius condition \(r(A) < 1\) holds, the solution is given by
9.8. Numpy Version#
Our first implementation will be in NumPy.
Once we have a NumPy version working, we will convert it to JAX and check the difference in the run times.
The code block below provides a function called create_sv_model() that returns a namedtuple containing arrays and other data that form the primitives of the problem.
It assumes that \(\{Z_t\}\) is a discretization of
SVModel = namedtuple('SVModel',
('P', 'hc_grid',
'Q', 'hd_grid',
'R', 'z_grid',
'β', 'γ', 'bar_σ', 'μ_c', 'μ_d'))
def create_sv_model(β=0.98, # discount factor
γ=2.5, # coefficient of risk aversion
I=14, # size of state space for h_c
ρ_c=0.9, # persistence parameter for h_c
σ_c=0.01, # volatility parameter for h_c
J=14, # size of state space for h_d
ρ_d=0.9, # persistence parameter for h_d
σ_d=0.01, # volatility parameter for h_d
K=14, # size of state space for z
bar_σ=0.01, # volatility scaling parameter
ρ_z=0.9, # persistence parameter for z
σ_z=0.01, # persistence parameter for z
μ_c=0.001, # mean growth of consumption
μ_d=0.005): # mean growth of dividends
mc = qe.tauchen(I, ρ_c, σ_c)
hc_grid = mc.state_values
P = mc.P
mc = qe.tauchen(J, ρ_d, σ_d)
hd_grid = mc.state_values
Q = mc.P
mc = qe.tauchen(K, ρ_z, σ_z)
z_grid = mc.state_values
R = mc.P
return SVModel(P=P, hc_grid=hc_grid,
Q=Q, hd_grid=hd_grid,
R=R, z_grid=z_grid,
β=β, γ=γ, bar_σ=bar_σ, μ_c=μ_c, μ_d=μ_d)
Now we provide a function to compute the matrix \(A\).
def compute_A(sv_model):
# Set up
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
I, J, K = len(hc_grid), len(hd_grid), len(z_grid)
N = I * J * K
# Reshape and broadcast over (i, j, k, i', j', k')
hc = np.reshape(hc_grid, (I, 1, 1, 1, 1, 1))
hd = np.reshape(hd_grid, (1, J, 1, 1, 1, 1))
z = np.reshape(z_grid, (1, 1, K, 1, 1, 1))
P = np.reshape(P, (I, 1, 1, I, 1, 1))
Q = np.reshape(Q, (1, J, 1, 1, J, 1))
R = np.reshape(R, (1, 1, K, 1, 1, K))
# Compute A and then reshape to create a matrix
a = μ_d - γ * μ_c
b = bar_σ**2 * (np.exp(2 * hd) + γ**2 * np.exp(2 * hc)) / 2
κ = np.exp(a + (1 - γ) * z + b)
A = β * κ * P * Q * R
A = np.reshape(A, (N, N))
return A
Here’s our function to compute the price-dividend ratio for the stochastic volatility model.
def sv_pd_ratio(sv_model, test_stable=True):
"""
Computes the price-dividend ratio of the asset for the stochastic volatility
model.
Parameters
----------
sv_model: an instance of Model
contains primitives
Returns
-------
v : array_like
price-dividend ratio
"""
# unpack
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
I, J, K = len(hc_grid), len(hd_grid), len(z_grid)
N = I * J * K
A = compute_A(sv_model)
# Make sure that a unique solution exists
if test_stable:
test_stability(A)
# Compute v
ones_array = np.ones(N)
Id = np.identity(N)
v = scipy.linalg.solve(Id - A, A @ ones_array)
# Reshape into an array of the form v[i, j, k]
v = np.reshape(v, (I, J, K))
return v
Let’s create an instance of the model and solve it.
sv_model = create_sv_model()
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
Let’s run it to compile.
start = time()
v = sv_pd_ratio(sv_model)
numpy_with_compile = time() - start
print("Numpy compile plus execution time = ", numpy_with_compile)
Numpy compile plus execution time = 0.84527587890625
Let’s run it again to remove the compile.
start = time()
v = sv_pd_ratio(sv_model)
numpy_without_compile = time() - start
print("Numpy execution time = ", numpy_without_compile)
Numpy execution time = 0.29814743995666504
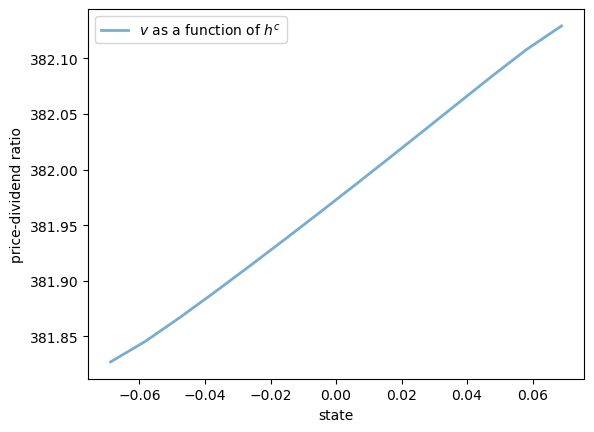
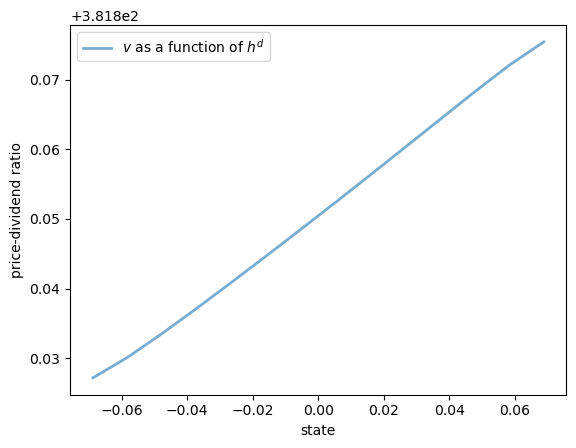
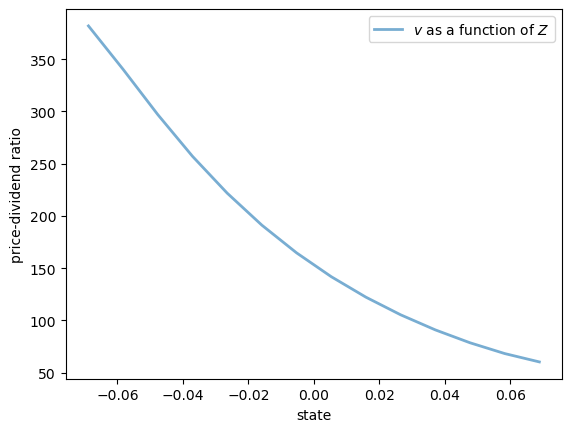
Here are some plots of the solution \(v\) along the three dimensions.
fig, ax = plt.subplots()
ax.plot(hc_grid, v[:, 0, 0], lw=2, alpha=0.6, label="$v$ as a function of $h^c$")
ax.set_ylabel("price-dividend ratio")
ax.set_xlabel("state")
ax.legend()
plt.show()
fig, ax = plt.subplots()
ax.plot(hd_grid, v[0, :, 0], lw=2, alpha=0.6, label="$v$ as a function of $h^d$")
ax.set_ylabel("price-dividend ratio")
ax.set_xlabel("state")
ax.legend()
plt.show()
fig, ax = plt.subplots()
ax.plot(z_grid, v[0, 0, :], lw=2, alpha=0.6, label="$v$ as a function of $Z$")
ax.set_ylabel("price-dividend ratio")
ax.set_xlabel("state")
ax.legend()
plt.show()
9.9. JAX Version#
Now let’s write a JAX version that is a simple transformation of the NumPy version.
(Below we will write a more efficient version using JAX’s ability to work with linear operators.)
def create_sv_model_jax(sv_model): # mean growth of dividends
# Take the contents of a NumPy sv_model instance
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
# Shift the arrays to the device (GPU if available)
hc_grid, hd_grid, z_grid = map(jax.device_put, (hc_grid, hd_grid, z_grid))
P, Q, R = map(jax.device_put, (P, Q, R))
# Create a new instance and return it
return SVModel(P=P, hc_grid=hc_grid,
Q=Q, hd_grid=hd_grid,
R=R, z_grid=z_grid,
β=β, γ=γ, bar_σ=bar_σ, μ_c=μ_c, μ_d=μ_d)
Here’s a function to compute \(A\).
We include the extra argument shapes to help the compiler understand the size of the arrays.
This is important when we JIT-compile the function below.
def compute_A_jax(sv_model, shapes):
# Set up
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
I, J, K = shapes
N = I * J * K
# Reshape and broadcast over (i, j, k, i', j', k')
hc = jnp.reshape(hc_grid, (I, 1, 1, 1, 1, 1))
hd = jnp.reshape(hd_grid, (1, J, 1, 1, 1, 1))
z = jnp.reshape(z_grid, (1, 1, K, 1, 1, 1))
P = jnp.reshape(P, (I, 1, 1, I, 1, 1))
Q = jnp.reshape(Q, (1, J, 1, 1, J, 1))
R = jnp.reshape(R, (1, 1, K, 1, 1, K))
# Compute A and then reshape to create a matrix
a = μ_d - γ * μ_c
b = bar_σ**2 * (jnp.exp(2 * hd) + γ**2 * jnp.exp(2 * hc)) / 2
κ = jnp.exp(a + (1 - γ) * z + b)
A = β * κ * P * Q * R
A = jnp.reshape(A, (N, N))
return A
Here’s the function that computes the solution.
def sv_pd_ratio_jax(sv_model, shapes):
"""
Computes the price-dividend ratio of the asset for the stochastic volatility
model.
Parameters
----------
sv_model: an instance of Model
contains primitives
Returns
-------
v : array_like
price-dividend ratio
"""
# unpack
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
I, J, K = len(hc_grid), len(hd_grid), len(z_grid)
shapes = I, J, K
N = I * J * K
A = compute_A_jax(sv_model, shapes)
# Compute v, reshape and return
ones_array = jnp.ones(N)
Id = jnp.identity(N)
v = jax.scipy.linalg.solve(Id - A, A @ ones_array)
return jnp.reshape(v, (I, J, K))
Now let’s target these functions for JIT-compilation, while using static_argnums to indicate that the function will need to be recompiled when shapes changes.
compute_A_jax = jax.jit(compute_A_jax, static_argnums=(1,))
sv_pd_ratio_jax = jax.jit(sv_pd_ratio_jax, static_argnums=(1,))
sv_model = create_sv_model()
sv_model_jax = create_sv_model_jax(sv_model)
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model_jax
shapes = len(hc_grid), len(hd_grid), len(z_grid)
Let’s see how long it takes to run with compile time included.
start = time()
v_jax = sv_pd_ratio_jax(sv_model_jax, shapes).block_until_ready()
jnp_with_compile = time() - start
print("JAX compile plus execution time = ", jnp_with_compile)
JAX compile plus execution time = 0.57698655128479
And now let’s see without compile time.
start = time()
v_jax = sv_pd_ratio_jax(sv_model_jax, shapes).block_until_ready()
jnp_without_compile = time() - start
print("JAX execution time = ", jnp_without_compile)
JAX execution time = 0.13494133949279785
Here’s the ratio of times:
jnp_without_compile / numpy_without_compile
0.4525993565881741
Let’s check that the NumPy and JAX versions realize the same solution.
v = jax.device_put(v)
print(jnp.allclose(v, v_jax))
True
9.10. A memory-efficient JAX version#
One problem with the code above is that we instantiate a matrix of size \(N = I \times J \times K\).
This quickly becomes impossible as \(I, J, K\) increase.
Fortunately, JAX makes it possible to solve for the price-dividend ratio without instantiating this large matrix.
The first step is to think of \(A\) not as a matrix, but rather as the linear operator that transforms \(g\) into \(Ag\).
def A(g, sv_model, shapes):
# Set up
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
I, J, K = shapes
# Reshape and broadcast over (i, j, k, i', j', k')
hc = jnp.reshape(hc_grid, (I, 1, 1, 1, 1, 1))
hd = jnp.reshape(hd_grid, (1, J, 1, 1, 1, 1))
z = jnp.reshape(z_grid, (1, 1, K, 1, 1, 1))
P = jnp.reshape(P, (I, 1, 1, I, 1, 1))
Q = jnp.reshape(Q, (1, J, 1, 1, J, 1))
R = jnp.reshape(R, (1, 1, K, 1, 1, K))
g = jnp.reshape(g, (1, 1, 1, I, J, K))
a = μ_d - γ * μ_c
b = bar_σ**2 * (jnp.exp(2 * hd) + γ**2 * jnp.exp(2 * hc)) / 2
κ = jnp.exp(a + (1 - γ) * z + b)
A = β * κ * P * Q * R
Ag = jnp.sum(A * g, axis=(3, 4, 5))
return Ag
Now we write a version of the solution function for the price-dividend ratio
that acts directly on the linear operator A.
def sv_pd_ratio_linop(sv_model, shapes):
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model
I, J, K = shapes
ones_array = jnp.ones((I, J, K))
# Set up the operator g -> (I - A) g
J = lambda g: g - A(g, sv_model, shapes)
# Solve v = (I - A)^{-1} A 1
A1 = A(ones_array, sv_model, shapes)
# Apply an iterative solver that works for linear operators
v = jax.scipy.sparse.linalg.bicgstab(J, A1)[0]
return v
Let’s target these functions for JIT compilation.
A = jax.jit(A, static_argnums=(2,))
sv_pd_ratio_linop = jax.jit(sv_pd_ratio_linop, static_argnums=(1,))
Let’s time the solution with compile time included.
start = time()
v_jax_linop = sv_pd_ratio_linop(sv_model, shapes).block_until_ready()
jnp_linop_with_compile = time() - start
print("JAX compile plus execution time = ", jnp_linop_with_compile)
JAX compile plus execution time = 0.2798018455505371
And now let’s see without compile time.
start = time()
v_jax_linop = sv_pd_ratio_linop(sv_model, shapes).block_until_ready()
jnp_linop_without_compile = time() - start
print("JAX execution time = ", jnp_linop_without_compile)
JAX execution time = 0.0060536861419677734
Let’s verify the solution again:
print(jnp.allclose(v, v_jax_linop))
True
Here’s the ratio of times between memory-efficient and direct version:
jnp_linop_without_compile / jnp_without_compile
0.04486161294027227
The speed is somewhat faster and, moreover, we can now work with much larger grids.
Here’s a moderately large example, where the state space has 15,625 elements.
sv_model = create_sv_model(I=25, J=25, K=25)
sv_model_jax = create_sv_model_jax(sv_model)
P, hc_grid, Q, hd_grid, R, z_grid, β, γ, bar_σ, μ_c, μ_d = sv_model_jax
shapes = len(hc_grid), len(hd_grid), len(z_grid)
%time _ = sv_pd_ratio_linop(sv_model_jax, shapes).block_until_ready()
%time _ = sv_pd_ratio_linop(sv_model_jax, shapes).block_until_ready()
CPU times: user 688 ms, sys: 29.5 ms, total: 718 ms
Wall time: 483 ms
CPU times: user 167 ms, sys: 1.78 ms, total: 169 ms
Wall time: 168 ms
The solution is computed relatively quickly and without memory issues.
Readers will find that they can push these numbers further, although we refrain from doing so here.