12. Optimal Savings II: Alternative Algorithms#
GPU
This lecture was built using a machine with access to a GPU — although it will also run without one.
Google Colab has a free tier with GPUs that you can access as follows:
Click on the “play” icon top right
Select Colab
Set the runtime environment to include a GPU
In Optimal Savings I: Value Function Iteration we solved a simple version of the household optimal savings problem via value function iteration (VFI) using JAX.
In this lecture we tackle exactly the same problem while adding in two alternative algorithms:
optimistic policy iteration (OPI) and
Howard policy iteration (HPI).
We will see that both of these algorithms outperform traditional VFI.
One reason for this is that the algorithms have good convergence properties.
Another is that one of them, HPI, is particularly well suited to pairing with JAX.
The reason is that HPI uses a relatively small number of computationally expensive steps, whereas VFI uses a longer sequence of small steps.
In other words, VFI is inherently more sequential than HPI, and sequential routines are hard to parallelize.
By comparison, HPI is less sequential – the small number of computationally intensive steps can be effectively parallelized by JAX.
This is particularly valuable when the underlying hardware includes a GPU.
Details on VFI, HPI and OPI can be found in this book, for which a PDF is freely available.
Here we assume readers have some knowledge of the algorithms and focus on computation.
For the details of the savings model, readers can refer to Optimal Savings I: Value Function Iteration.
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
We will use the following imports:
import quantecon as qe
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
from time import time
Let’s check the GPU we are running.
!nvidia-smi
Fri Jun 26 06:49:20 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.105.08 Driver Version: 580.105.08 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 30C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
We’ll use 64 bit floats to gain extra precision.
jax.config.update("jax_enable_x64", True)
12.1. Model primitives#
First we define a model that stores parameters and grids.
The following code is repeated from Optimal Savings I: Value Function Iteration.
def create_consumption_model(R=1.01, # Gross interest rate
β=0.98, # Discount factor
γ=2, # CRRA parameter
w_min=0.01, # Min wealth
w_max=5.0, # Max wealth
w_size=150, # Grid side
ρ=0.9, ν=0.1, y_size=100): # Income parameters
"""
A function that takes in parameters and returns parameters and grids
for the optimal savings problem.
"""
# Build grids and transition probabilities
w_grid = jnp.linspace(w_min, w_max, w_size)
mc = qe.tauchen(n=y_size, rho=ρ, sigma=ν)
y_grid, Q = jnp.exp(mc.state_values), mc.P
# Pack and return
params = β, R, γ
sizes = w_size, y_size
arrays = w_grid, y_grid, jnp.array(Q)
return params, sizes, arrays
Here’s the right hand side of the Bellman equation:
def _B(v, params, arrays, i, j, ip):
"""
The right-hand side of the Bellman equation before maximization, which takes
the form
B(w, y, w′) = u(Rw + y - w′) + β Σ_y′ v(w′, y′) Q(y, y′)
The indices are (i, j, ip) -> (w, y, w′).
"""
β, R, γ = params
w_grid, y_grid, Q = arrays
w, y, wp = w_grid[i], y_grid[j], w_grid[ip]
c = R * w + y - wp
EV = jnp.sum(v[ip, :] * Q[j, :])
return jnp.where(c > 0, c**(1-γ)/(1-γ) + β * EV, -jnp.inf)
Now we successively apply vmap to vectorize \(B\) by simulating nested loops.
B_1 = jax.vmap(_B, in_axes=(None, None, None, None, None, 0))
B_2 = jax.vmap(B_1, in_axes=(None, None, None, None, 0, None))
B_vmap = jax.vmap(B_2, in_axes=(None, None, None, 0, None, None))
Here’s a fully vectorized version of \(B\).
def B(v, params, sizes, arrays):
w_size, y_size = sizes
w_indices, y_indices = jnp.arange(w_size), jnp.arange(y_size)
return B_vmap(v, params, arrays, w_indices, y_indices, w_indices)
B = jax.jit(B, static_argnums=(2,))
12.2. Operators#
Here’s the Bellman operator \(T\)
def T(v, params, sizes, arrays):
"The Bellman operator."
return jnp.max(B(v, params, sizes, arrays), axis=-1)
T = jax.jit(T, static_argnums=(2,))
The next function computes a \(v\)-greedy policy given \(v\)
def get_greedy(v, params, sizes, arrays):
"Computes a v-greedy policy, returned as a set of indices."
return jnp.argmax(B(v, params, sizes, arrays), axis=-1)
get_greedy = jax.jit(get_greedy, static_argnums=(2,))
We define a function to compute the current rewards \(r_\sigma\) given policy \(\sigma\), which is defined as the vector
def _compute_r_σ(σ, params, arrays, i, j):
"""
With indices (i, j) -> (w, y) and wp = σ[i, j], compute
r_σ[i, j] = u(Rw + y - wp)
which gives current rewards under policy σ.
"""
# Unpack model
β, R, γ = params
w_grid, y_grid, Q = arrays
# Compute r_σ[i, j]
w, y, wp = w_grid[i], y_grid[j], w_grid[σ[i, j]]
c = R * w + y - wp
r_σ = c**(1-γ)/(1-γ)
return r_σ
Now we successively apply vmap to simulate nested loops.
r_1 = jax.vmap(_compute_r_σ, in_axes=(None, None, None, None, 0))
r_σ_vmap = jax.vmap(r_1, in_axes=(None, None, None, 0, None))
Here’s a fully vectorized version of \(r_\sigma\).
def compute_r_σ(σ, params, sizes, arrays):
w_size, y_size = sizes
w_indices, y_indices = jnp.arange(w_size), jnp.arange(y_size)
return r_σ_vmap(σ, params, arrays, w_indices, y_indices)
compute_r_σ = jax.jit(compute_r_σ, static_argnums=(2,))
Now we define the policy operator \(T_\sigma\) going through similar steps
def _T_σ(v, σ, params, arrays, i, j):
"The σ-policy operator."
# Unpack model
β, R, γ = params
w_grid, y_grid, Q = arrays
r_σ = _compute_r_σ(σ, params, arrays, i, j)
# Calculate the expected sum Σ_jp v[σ[i, j], jp] * Q[i, j, jp]
EV = jnp.sum(v[σ[i, j], :] * Q[j, :])
return r_σ + β * EV
T_1 = jax.vmap(_T_σ, in_axes=(None, None, None, None, None, 0))
T_σ_vmap = jax.vmap(T_1, in_axes=(None, None, None, None, 0, None))
def T_σ(v, σ, params, sizes, arrays):
w_size, y_size = sizes
w_indices, y_indices = jnp.arange(w_size), jnp.arange(y_size)
return T_σ_vmap(v, σ, params, arrays, w_indices, y_indices)
T_σ = jax.jit(T_σ, static_argnums=(3,))
The function below computes the value \(v_\sigma\) of following policy \(\sigma\).
This lifetime value is a function \(v_\sigma\) that satisfies
We wish to solve this equation for \(v_\sigma\).
Suppose we define the linear operator \(L_\sigma\) by
With this notation, the problem is to solve for \(v\) via
In vector for this is \(L_\sigma v = r_\sigma\), which tells us that the function we seek is
JAX allows us to solve linear systems defined in terms of operators; the first step is to define the function \(L_{\sigma}\).
def _L_σ(v, σ, params, arrays, i, j):
"""
Here we set up the linear map v -> L_σ v, where
(L_σ v)(w, y) = v(w, y) - β Σ_y′ v(σ(w, y), y′) Q(y, y′)
"""
# Unpack
β, R, γ = params
w_grid, y_grid, Q = arrays
# Compute and return v[i, j] - β Σ_jp v[σ[i, j], jp] * Q[j, jp]
return v[i, j] - β * jnp.sum(v[σ[i, j], :] * Q[j, :])
L_1 = jax.vmap(_L_σ, in_axes=(None, None, None, None, None, 0))
L_σ_vmap = jax.vmap(L_1, in_axes=(None, None, None, None, 0, None))
def L_σ(v, σ, params, sizes, arrays):
w_size, y_size = sizes
w_indices, y_indices = jnp.arange(w_size), jnp.arange(y_size)
return L_σ_vmap(v, σ, params, arrays, w_indices, y_indices)
L_σ = jax.jit(L_σ, static_argnums=(3,))
Now we can define a function to compute \(v_{\sigma}\)
def get_value(σ, params, sizes, arrays):
"Get the value v_σ of policy σ by inverting the linear map L_σ."
# Unpack
β, R, γ = params
w_size, y_size = sizes
w_grid, y_grid, Q = arrays
r_σ = compute_r_σ(σ, params, sizes, arrays)
# Reduce L_σ to a function in v
partial_L_σ = lambda v: L_σ(v, σ, params, sizes, arrays)
return jax.scipy.sparse.linalg.bicgstab(partial_L_σ, r_σ)[0]
get_value = jax.jit(get_value, static_argnums=(2,))
12.3. Iteration#
We use successive approximation for VFI.
def successive_approx_jax(T, # Operator (callable)
x_0, # Initial condition
tol=1e-6, # Error tolerance
max_iter=10_000): # Max iteration bound
def update(inputs):
k, x, error = inputs
x_new = T(x)
error = jnp.max(jnp.abs(x_new - x))
return k + 1, x_new, error
def condition_function(inputs):
k, x, error = inputs
return jnp.logical_and(error > tol, k < max_iter)
k, x, error = jax.lax.while_loop(condition_function,
update,
(1, x_0, tol + 1))
return x
successive_approx_jax = jax.jit(successive_approx_jax, static_argnums=(0,))
For OPI we’ll add a compiled routine that computes \(T_σ^m v\).
def iterate_policy_operator(σ, v, m, params, sizes, arrays):
def update(i, v):
v = T_σ(v, σ, params, sizes, arrays)
return v
v = jax.lax.fori_loop(0, m, update, v)
return v
iterate_policy_operator = jax.jit(iterate_policy_operator,
static_argnums=(4,))
12.4. Solvers#
Now we define the solvers, which implement VFI, HPI and OPI.
Here’s VFI.
def value_function_iteration(model, tol=1e-5):
"""
Implements value function iteration.
"""
params, sizes, arrays = model
vz = jnp.zeros(sizes)
_T = lambda v: T(v, params, sizes, arrays)
v_star = successive_approx_jax(_T, vz, tol=tol)
return get_greedy(v_star, params, sizes, arrays)
For OPI we will use a compiled JAX lax.while_loop operation to speed execution.
def opi_loop(params, sizes, arrays, m, tol, max_iter):
"""
Implements optimistic policy iteration (see dp.quantecon.org) with
step size m.
"""
v_init = jnp.zeros(sizes)
def condition_function(inputs):
i, v, error = inputs
return jnp.logical_and(error > tol, i < max_iter)
def update(inputs):
i, v, error = inputs
last_v = v
σ = get_greedy(v, params, sizes, arrays)
v = iterate_policy_operator(σ, v, m, params, sizes, arrays)
error = jnp.max(jnp.abs(v - last_v))
i += 1
return i, v, error
num_iter, v, error = jax.lax.while_loop(condition_function,
update,
(0, v_init, tol + 1))
return get_greedy(v, params, sizes, arrays)
opi_loop = jax.jit(opi_loop, static_argnums=(1,))
Here’s a friendly interface to OPI
def optimistic_policy_iteration(model, m=10, tol=1e-5, max_iter=10_000):
params, sizes, arrays = model
σ_star = opi_loop(params, sizes, arrays, m, tol, max_iter)
return σ_star
Here’s HPI.
def howard_policy_iteration(model, maxiter=250):
"""
Implements Howard policy iteration (see dp.quantecon.org)
"""
params, sizes, arrays = model
σ = jnp.zeros(sizes, dtype=int)
i, error = 0, 1.0
while error > 0 and i < maxiter:
v_σ = get_value(σ, params, sizes, arrays)
σ_new = get_greedy(v_σ, params, sizes, arrays)
error = jnp.max(jnp.abs(σ_new - σ))
σ = σ_new
i = i + 1
print(f"Concluded loop {i} with error {error}.")
return σ
12.5. Tests#
Let’s create a model for consumption, and plot the resulting optimal policy function using all the three algorithms and also check the time taken by each solver.
model = create_consumption_model()
# Unpack
params, sizes, arrays = model
β, R, γ = params
w_size, y_size = sizes
w_grid, y_grid, Q = arrays
print("Starting HPI.")
start = time()
σ_star_hpi = howard_policy_iteration(model).block_until_ready()
hpi_with_compile = time() - start
print(f"HPI completed in {hpi_with_compile} seconds.")
Starting HPI.
Concluded loop 1 with error 77.
Concluded loop 2 with error 53.
Concluded loop 3 with error 28.
Concluded loop 4 with error 17.
Concluded loop 5 with error 8.
Concluded loop 6 with error 4.
Concluded loop 7 with error 1.
Concluded loop 8 with error 1.
Concluded loop 9 with error 1.
Concluded loop 10 with error 0.
HPI completed in 1.1231391429901123 seconds.
We run it again to get rid of compile time.
start = time()
σ_star_hpi = howard_policy_iteration(model).block_until_ready()
hpi_without_compile = time() - start
print(f"HPI completed in {hpi_without_compile} seconds.")
Concluded loop 1 with error 77.
Concluded loop 2 with error 53.
Concluded loop 3 with error 28.
Concluded loop 4 with error 17.
Concluded loop 5 with error 8.
Concluded loop 6 with error 4.
Concluded loop 7 with error 1.
Concluded loop 8 with error 1.
Concluded loop 9 with error 1.
Concluded loop 10 with error 0.
HPI completed in 0.11657595634460449 seconds.
fig, ax = plt.subplots()
ax.plot(w_grid, w_grid, "k--", label="45")
ax.plot(w_grid, w_grid[σ_star_hpi[:, 1]], label="$\\sigma^{*}_{HPI}(\cdot, y_1)$")
ax.plot(w_grid, w_grid[σ_star_hpi[:, -1]], label="$\\sigma^{*}_{HPI}(\cdot, y_N)$")
ax.legend()
plt.show()
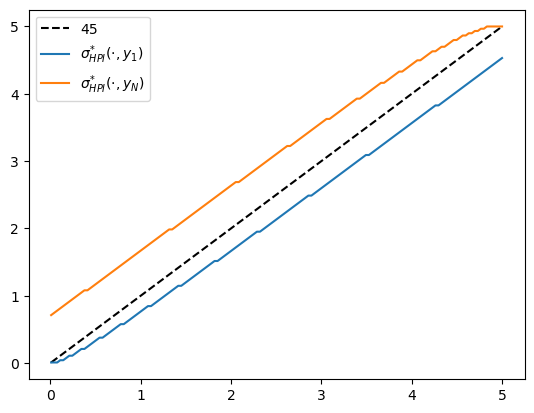
Fig. 12.1 Optimal policy function (HPI)#
print("Starting VFI.")
start = time()
σ_star_vfi = value_function_iteration(model).block_until_ready()
vfi_with_compile = time() - start
print(f"VFI completed in {vfi_with_compile} seconds.")
Starting VFI.
VFI completed in 0.516956090927124 seconds.
We run it again to eliminate compile time.
start = time()
σ_star_vfi = value_function_iteration(model).block_until_ready()
vfi_without_compile = time() - start
print(f"VFI completed in {vfi_without_compile} seconds.")
VFI completed in 0.41559648513793945 seconds.
fig, ax = plt.subplots()
ax.plot(w_grid, w_grid, "k--", label="45")
ax.plot(w_grid, w_grid[σ_star_vfi[:, 1]], label="$\\sigma^{*}_{VFI}(\cdot, y_1)$")
ax.plot(w_grid, w_grid[σ_star_vfi[:, -1]], label="$\\sigma^{*}_{VFI}(\cdot, y_N)$")
ax.legend()
plt.show()
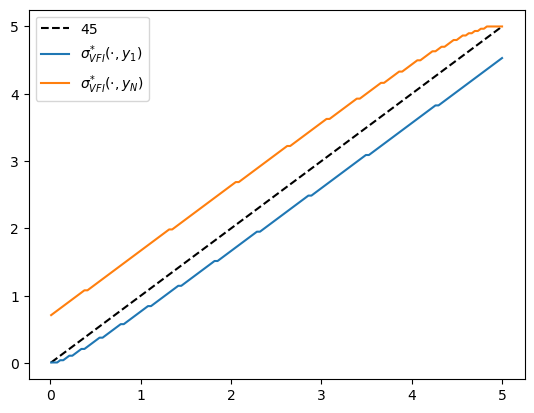
Fig. 12.2 Optimal policy function (VFI)#
print("Starting OPI.")
start = time()
σ_star_opi = optimistic_policy_iteration(model, m=100).block_until_ready()
opi_with_compile = time() - start
print(f"OPI completed in {opi_with_compile} seconds.")
Starting OPI.
OPI completed in 0.458038330078125 seconds.
Let’s run it again to get rid of compile time.
start = time()
σ_star_opi = optimistic_policy_iteration(model, m=100).block_until_ready()
opi_without_compile = time() - start
print(f"OPI completed in {opi_without_compile} seconds.")
OPI completed in 0.1267378330230713 seconds.
fig, ax = plt.subplots()
ax.plot(w_grid, w_grid, "k--", label="45")
ax.plot(w_grid, w_grid[σ_star_opi[:, 1]], label="$\\sigma^{*}_{OPI}(\cdot, y_1)$")
ax.plot(w_grid, w_grid[σ_star_opi[:, -1]], label="$\\sigma^{*}_{OPI}(\cdot, y_N)$")
ax.legend()
plt.show()
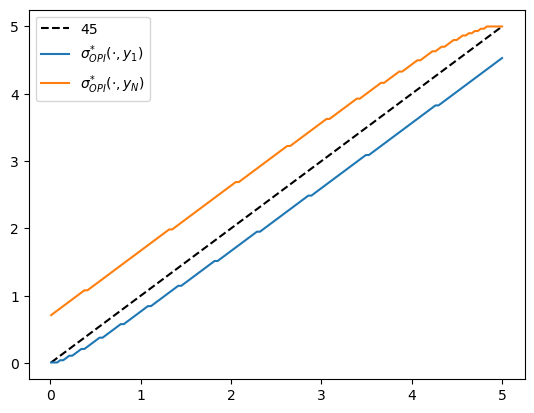
Fig. 12.3 Optimal policy function (OPI)#
We observe that all the solvers produce the same output from the above three plots.
Now, let’s create a plot to visualize the time differences among these algorithms.
def run_algorithm(algorithm, model, **kwargs):
result = algorithm(model, **kwargs)
# Now time it without compile time
start = time()
result = algorithm(model, **kwargs).block_until_ready()
algorithm_without_compile = time() - start
print(f"{algorithm.__name__} completed in {algorithm_without_compile:.2f} seconds.")
return result, algorithm_without_compile
σ_pi, pi_time = run_algorithm(howard_policy_iteration, model)
σ_vfi, vfi_time = run_algorithm(value_function_iteration, model, tol=1e-5)
Concluded loop 1 with error 77.
Concluded loop 2 with error 53.
Concluded loop 3 with error 28.
Concluded loop 4 with error 17.
Concluded loop 5 with error 8.
Concluded loop 6 with error 4.
Concluded loop 7 with error 1.
Concluded loop 8 with error 1.
Concluded loop 9 with error 1.
Concluded loop 10 with error 0.
Concluded loop 1 with error 77.
Concluded loop 2 with error 53.
Concluded loop 3 with error 28.
Concluded loop 4 with error 17.
Concluded loop 5 with error 8.
Concluded loop 6 with error 4.
Concluded loop 7 with error 1.
Concluded loop 8 with error 1.
Concluded loop 9 with error 1.
Concluded loop 10 with error 0.
howard_policy_iteration completed in 0.08 seconds.
value_function_iteration completed in 0.39 seconds.
m_vals = range(5, 600, 40)
opi_times = []
for m in m_vals:
σ_opi, opi_time = run_algorithm(optimistic_policy_iteration,
model, m=m, tol=1e-5)
opi_times.append(opi_time)
optimistic_policy_iteration completed in 0.38 seconds.
optimistic_policy_iteration completed in 0.12 seconds.
optimistic_policy_iteration completed in 0.12 seconds.
optimistic_policy_iteration completed in 0.14 seconds.
optimistic_policy_iteration completed in 0.17 seconds.
optimistic_policy_iteration completed in 0.21 seconds.
optimistic_policy_iteration completed in 0.24 seconds.
optimistic_policy_iteration completed in 0.28 seconds.
optimistic_policy_iteration completed in 0.32 seconds.
optimistic_policy_iteration completed in 0.35 seconds.
optimistic_policy_iteration completed in 0.39 seconds.
optimistic_policy_iteration completed in 0.42 seconds.
optimistic_policy_iteration completed in 0.46 seconds.
optimistic_policy_iteration completed in 0.49 seconds.
optimistic_policy_iteration completed in 0.53 seconds.
fig, ax = plt.subplots()
ax.plot(m_vals,
jnp.full(len(m_vals), hpi_without_compile),
lw=2, label="Howard policy iteration")
ax.plot(m_vals,
jnp.full(len(m_vals), vfi_without_compile),
lw=2, label="value function iteration")
ax.plot(m_vals, opi_times,
lw=2, label="optimistic policy iteration")
ax.legend(frameon=False, loc='lower right')
ax.set_xlabel("$m$")
ax.set_ylabel("time")
plt.show()
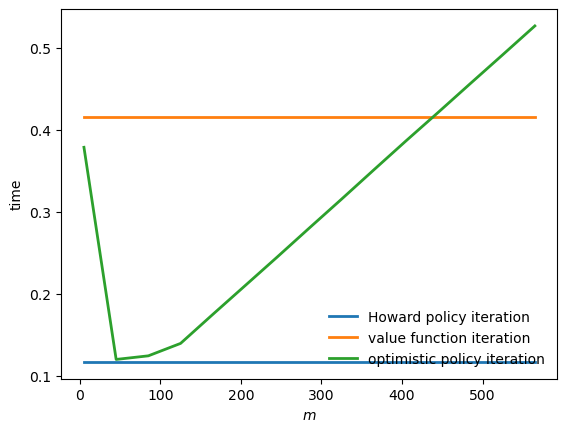
Fig. 12.4 Solver times#