28. Parallelizing the Algorithm#
28.1. Overview#
In the previous lectures, we implemented the Schelling segregation model using NumPy and JAX.
Both implementations are fundamentally sequential: agents update one at a time, and each agent’s move changes the state for subsequent agents.
In this lecture, we introduce a parallel algorithm that fully leverages JAX’s ability to perform vectorized operations across all agents simultaneously.
The algorithm is in some sense less elegant, but it still converges in a relatively small number of steps — and its parallel nature allows us to exploit the full power of JAX.
import matplotlib.pyplot as plt
import numpy as np
import jax
import jax.numpy as jnp
from jax import random, jit, vmap
from functools import partial
from typing import NamedTuple
import time
28.2. Setup#
We use the same parameters as before, with the addition of num_candidates —
the number of candidate locations each agent considers per iteration:
class Params(NamedTuple):
num_of_type_0: int = 1000 # number of agents of type 0 (orange)
num_of_type_1: int = 1000 # number of agents of type 1 (green)
num_neighbors: int = 10 # number of neighbors
max_other_type: int = 6 # max number of different-type neighbors tolerated
num_candidates: int = 3 # candidate locations per agent per iteration
params = Params()
The following functions are repeated from the previous lecture:
def initialize_state(key, params):
n = params.num_of_type_0 + params.num_of_type_1
locations = random.uniform(key, (n, 2))
types = jnp.concatenate([jnp.zeros(params.num_of_type_0, dtype=int),
jnp.ones(params.num_of_type_1, dtype=int)])
return locations, types
@partial(jit, static_argnames=('params',))
def is_happy(loc, agent_idx, locations, types, params):
" True if an agent at loc has at most max_other_type different-type neighbors. "
distances = jnp.sum((loc - locations)**2, axis=1)
distances = distances.at[agent_idx].set(jnp.inf)
_, neighbors = jax.lax.top_k(-distances, params.num_neighbors)
num_other = jnp.sum(types[neighbors] != types[agent_idx])
return num_other <= params.max_other_type
@partial(jit, static_argnames=('params',))
def get_unhappy_agents(locations, types, params):
" Return a boolean array indicating which agents are unhappy. "
n = params.num_of_type_0 + params.num_of_type_1
def is_unhappy(i):
return ~is_happy(locations[i], i, locations, types, params)
return vmap(is_unhappy)(jnp.arange(n))
28.3. The Parallel Algorithm#
Our aim is to update all agents at the same time, rather than sequentially.
To do this we
Generate candidate locations for all agents in parallel
Update all agents simultaneously — happy agents stay put, unhappy agents move if a happy candidate was found
We offer a fixed number of candidates to all agents, so that the parallel threads do the same amount of work and hence run at the same speed.
This approach is well-suited to GPU execution, where thousands of operations can run concurrently.
There are two trade-offs compared to the sequential algorithm.
First, the sequential algorithm guarantees that each agent finds a happy location before moving on.
The parallel algorithm instead proposes a fixed number of candidate locations per agent per iteration.
If none of the candidates make the agent happy, the agent stays put and tries again next iteration.
This means the parallel algorithm may need more iterations.
Second, because we update all agents at once, the agents have less information — they are predicting the next period distribution from the current one.
We hope that, nonetheless, the algorithm will converge.
The update_agent_location function below performs all computation (generating
candidates for all agents, regardless of current status, checking happiness at
each candidate) upfront before making the final decision about whether to move.
This may seem wasteful but it’s actually optimal for parallel execution: on GPUs, all threads execute the same instructions in lockstep, so conditional branches don’t skip work.
@partial(jit, static_argnames=('params',))
def update_agent_location(i, locations, types, key, params):
"""
Consider current location and num_candidates random alternatives.
Return the first happy one. Already happy agents stay put.
"""
current_loc = locations[i, :]
# Build candidate list: current location + num_candidates random ones
random_locs = random.uniform(key, (params.num_candidates, 2))
candidate_locations = jnp.vstack([current_loc[None, :], random_locs])
# Check happiness at each candidate (in parallel)
def check_candidate(loc):
return is_happy(loc, i, locations, types, params)
happy_at = vmap(check_candidate)(candidate_locations)
# Return the first happy candidate location.
# Already happy agents select candidate_locations[0] and stay put.
# If no candidate is happy, argmax returns 0 and the agent stays put.
return candidate_locations[jnp.argmax(happy_at)]
The code above is for one agent.
The next function uses vmap to apply this update rule to determine the new
location array across all agents.
@partial(jit, static_argnames=('params',))
def parallel_update_step(locations, types, key, params):
"""
One step of the parallel algorithm: for each agent, find a happy
candidate location (in parallel). Happy agents stay put, unhappy
agents search for new locations.
"""
n = params.num_of_type_0 + params.num_of_type_1
keys = random.split(key, n + 1)
key = keys[0]
agent_keys = keys[1:]
# Closure: wraps update_agent_location so vmap can map over a single argument
def update_one_agent(i):
return update_agent_location(i, locations, types, agent_keys[i], params)
new_locations = vmap(update_one_agent)(jnp.arange(n))
return new_locations, key
Here’s the outer loop, which updates the population until convergence.
By using jax.lax.while_loop, we can JIT-compile the entire simulation,
avoiding Python loop overhead.
@partial(jit, static_argnames=('params', 'max_iter'))
def parallel_simulation_loop(locations, types, key, params, max_iter):
def while_test(state):
locations, key, iteration = state
unhappy = get_unhappy_agents(locations, types, params)
return (iteration < max_iter) & jnp.any(unhappy)
def update(state):
locations, key, iteration = state
locations, key = parallel_update_step(locations, types, key, params)
return locations, key, iteration + 1
locations, _, iteration = jax.lax.while_loop(
while_test, update, (locations, key, 0)
)
converged = ~jnp.any(get_unhappy_agents(locations, types, params))
return locations, iteration, converged
def run_parallel_simulation(params, max_iter=100_000, seed=42):
key = random.key(seed)
key, init_key = random.split(key)
locations, types = initialize_state(init_key, params)
plot_distribution(locations, types, 'Initial distribution')
start_time = time.time()
locations, iteration, converged = parallel_simulation_loop(locations, types, key, params, max_iter)
elapsed = time.time() - start_time
plot_distribution(locations, types, f'Iteration {int(iteration)}')
if converged:
print(f'Converged in {elapsed:.2f} seconds after {int(iteration)} iterations.')
else:
print('Hit iteration bound and terminated.')
return locations, types
28.4. Results#
Let’s warm up the JIT-compiled functions and run the simulation:
key = random.key(0)
key, init_key = random.split(key)
test_locations, test_types = initialize_state(init_key, params)
_ = is_happy(test_locations[0], 0, test_locations, test_types, params)
_ = get_unhappy_agents(test_locations, test_types, params)
key, subkey = random.split(key)
_ = update_agent_location(0, test_locations, test_types, subkey, params)
key, subkey = random.split(key)
_, _ = parallel_update_step(test_locations, test_types, subkey, params)
print("JAX functions compiled and ready!")
JAX functions compiled and ready!
locations, types = run_parallel_simulation(params)
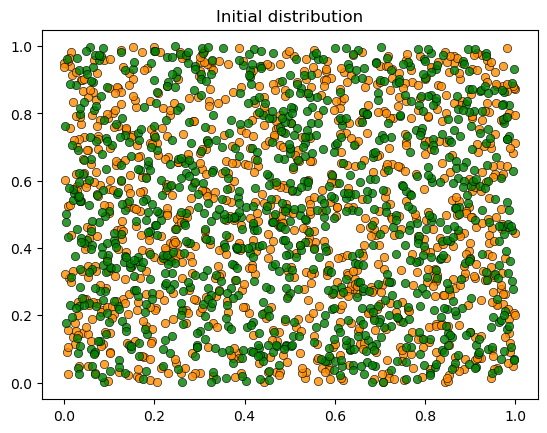
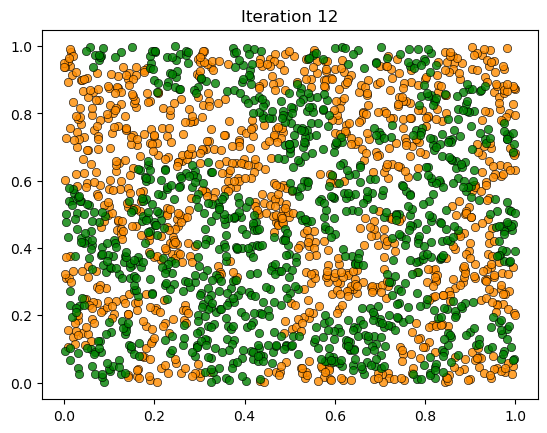
Converged in 0.69 seconds after 12 iterations.
You can compare the execution time with the NumPy and JAX sequential results from the previous lectures.
28.5. Discussion#
The parallel approach processes all agents simultaneously each iteration.
While it may require more iterations (since agents get only a fixed number of candidate locations), each iteration leverages massive parallelism.
This trade-off strongly favors parallelism on GPUs, where thousands of threads can evaluate candidate locations concurrently.
The key lesson is that simply porting code to JAX doesn’t automatically make it faster — algorithms often need to be restructured for parallelism.